機器學習 - 訓練/測試
評估您的模型
在機器學習中,我們建立模型來預測某些事件的結果,就像在前一章中,我們預測了已知汽車重量和發動機尺寸時的二氧化碳排放量。
為了衡量模型是否足夠好,我們可以使用一種叫做“訓練/測試”的方法。
什麼是訓練/測試?
訓練/測試是一種衡量模型準確性的方法。
它之所以被稱為訓練/測試,是因為您將資料集分成兩部分:訓練集和測試集。
80% 用於訓練,20% 用於測試。
您使用訓練集來**訓練**模型。
您使用測試集來**測試**模型。
**訓練**模型意味著**建立**模型。
**測試**模型意味著測試模型的準確性。
從資料集開始
從您想要測試的資料集開始。
我們的資料集展示了商店中 100 名顧客及其購物習慣。
示例
import numpy
import matplotlib.pyplot as plt
numpy.random.seed(2)
x = numpy.random.normal(3, 1, 100)
y = numpy.random.normal(150, 40, 100) / x
plt.scatter(x, y)
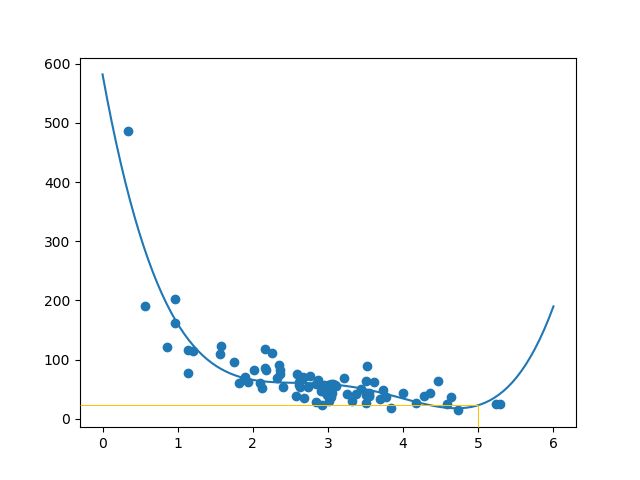
plt.show()
結果
x 軸表示購買前停留的分鐘數。
y 軸表示購買時花費的金額。
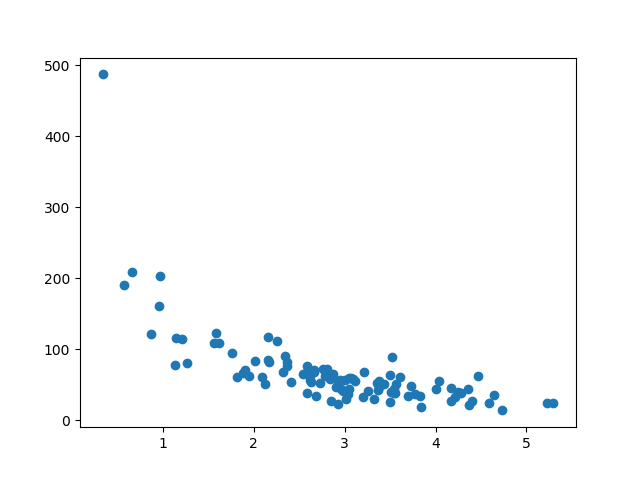
分成訓練/測試
**訓練**集應該是原始資料中 80% 的隨機選擇。
**測試**集應該是剩餘的 20%。
train_x = x[:80]
train_y = y[:80]
test_x = x[80:]
test_y = y[80:]
顯示訓練集
使用訓練集顯示相同的散點圖
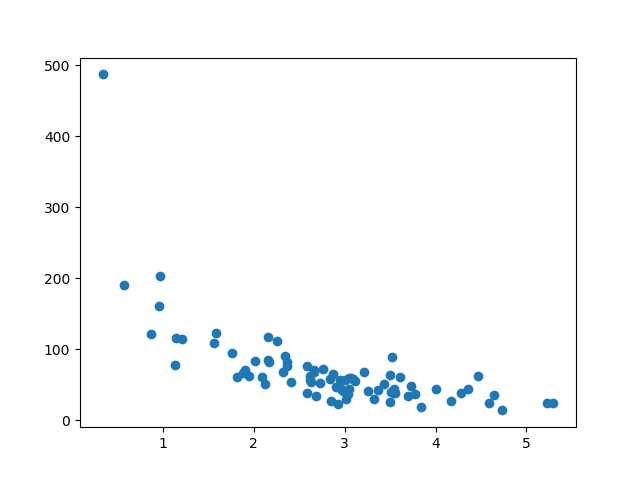
顯示測試集
為了確保測試集沒有完全不同,我們也會檢視測試集。
擬合數據集
這個資料集看起來像什麼?在我看來,我認為最適合的將是多項式迴歸,所以讓我們畫一條多項式迴歸線。
要繪製一條穿過資料點的線,我們使用 matplotlib 模組的 plot() 方法。
示例
繪製一條穿過資料點的多項式迴歸線
import numpy
import matplotlib.pyplot as plt
numpy.random.seed(2)
x = numpy.random.normal(3, 1, 100)
y = numpy.random.normal(150, 40, 100) / x
train_x = x[:80]
train_y = y[:80]
test_x = x[80:]
test_y = y[80:]
mymodel = numpy.poly1d(numpy.polyfit(train_x, train_y, 4))
myline = numpy.linspace(0, 6, 100)
plt.scatter(train_x, train_y)
plt.plot(myline, mymodel(myline))
plt.show()
結果
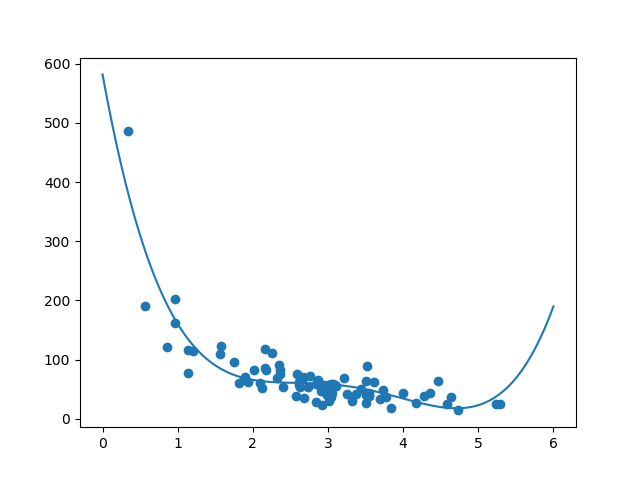
結果可以支援我對資料集適合多項式迴歸的建議,儘管如果我們嘗試預測資料集之外的值,它會給出一些奇怪的結果。例如:該線表示在商店停留 6 分鐘的顧客將進行價值 200 的購買。這可能是一種過擬合的跡象。
但是 R 方分數呢?R 方分數是衡量我的資料集擬合模型程度的一個很好的指標。
R2
還記得 R2,也稱為 R 方嗎?
它衡量 x 軸和 y 軸之間的關係,其值範圍從 0 到 1,其中 0 表示沒有關係,1 表示完全相關。
sklearn 模組有一個名為 r2_score() 的方法,可以幫助我們找到這種關係。
在這種情況下,我們希望衡量顧客在商店停留的分鐘數與他們花費的金額之間的關係。
示例
我的訓練資料在多項式迴歸中的擬合程度如何?
import numpy
from sklearn.metrics import r2_score
numpy.random.seed(2)
x = numpy.random.normal(3, 1, 100)
y = numpy.random.normal(150, 40, 100) / x
train_x = x[:80]
train_y = y[:80]
test_x = x[80:]
test_y = y[80:]
mymodel = numpy.poly1d(numpy.polyfit(train_x, train_y, 4))
r2 = r2_score(train_y, mymodel(train_x))
print(r2)
自己動手試一試 »
注意:結果 0.799 表明存在良好的關係。
引入測試集
現在我們已經建立了一個還不錯的模型,至少在訓練資料方面是這樣。
現在我們還想用測試資料來測試模型,看看它是否給出相同的結果。
示例
讓我們找出使用測試資料時的 R2 分數
import numpy
from sklearn.metrics import r2_score
numpy.random.seed(2)
x = numpy.random.normal(3, 1, 100)
y = numpy.random.normal(150, 40, 100) / x
train_x = x[:80]
train_y = y[:80]
test_x = x[80:]
test_y = y[80:]
mymodel = numpy.poly1d(numpy.polyfit(train_x, train_y, 4))
r2 = r2_score(test_y, mymodel(test_x))
print(r2)
自己動手試一試 »
注意:結果 0.809 表明模型也擬合測試集,我們有信心可以使用該模型來預測未來值。
預測值
既然我們已經確定我們的模型是好的,我們就可以開始預測新值了。
該示例預測顧客將花費 22.88 美元,這似乎與圖表相符。