機器學習 - Bootstrap Aggregation (Bagging)
在此頁面上,W3schools.com 與 紐約資料科學學院 合作,為我們的學生提供數字培訓內容。
Bagging
決策樹等方法在訓練集上容易過擬合,這可能導致在新資料上做出錯誤的預測。
Bootstrap Aggregation (Bagging) 是一種整合方法,旨在解決分類或迴歸問題中的過擬合問題。Bagging 旨在提高機器學習演算法的準確性和效能。它透過對原始資料集進行有放回的隨機抽樣,並對每個子集擬合分類器(用於分類)或迴歸器(用於迴歸)。然後,透過多數投票(用於分類)或平均(用於迴歸)聚合每個子集的預測,從而提高預測準確性。
評估基礎分類器
為了瞭解 Bagging 如何提高模型效能,我們必須首先評估基礎分類器在資料集上的表現。如果您不瞭解決策樹,請在繼續之前回顧決策樹課程,因為 Bagging 是該概念的延續。
我們將嘗試識別 Sklearn 酒資料集中不同類別的葡萄酒。
讓我們首先匯入必要的模組。來自 sklearn 匯入資料集
來自 sklearn.model_selection 匯入 train_test_split
來自 sklearn.metrics 匯入 accuracy_score
來自 sklearn.tree 匯入 DecisionTreeClassifier
接下來,我們需要載入資料並將其儲存到 X(輸入特徵)和 y(目標)中。引數 as_frame 設定為 True,這樣在載入資料時就不會丟失特徵名稱。(sklearn 版本早於 0.23 必須跳過 as_frame 引數,因為它不支援)
data = datasets.load_wine(as_frame = True)
X = data.data
y = data.target
為了在未見過的資料上正確評估我們的模型,我們需要將 X 和 y 分割成訓練集和測試集。有關分割資料的資訊,請參閱訓練/測試課程。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 22)
準備好資料後,我們現在可以例項化一個基礎分類器並將其擬合到訓練資料中。
dtree = DecisionTreeClassifier(random_state = 22)
dtree.fit(X_train,y_train)
結果
DecisionTreeClassifier(random_state=22)
我們現在可以預測未見測試集的葡萄酒類別,並評估模型效能。
y_pred = dtree.predict(X_test)
print("訓練資料準確率:",accuracy_score(y_true = y_train, y_pred = dtree.predict(X_train)))
print("測試資料準確率:",accuracy_score(y_true = y_test, y_pred = y_pred))
結果
訓練資料準確率:1.0
測試資料準確率:0.8222222222222222
示例
匯入必要資料並評估基礎分類器效能。
來自 sklearn 匯入資料集
來自 sklearn.model_selection 匯入 train_test_split
來自 sklearn.metrics 匯入 accuracy_score
來自 sklearn.tree 匯入 DecisionTreeClassifier
data = datasets.load_wine(as_frame = True)
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 22)
dtree = DecisionTreeClassifier(random_state = 22)
dtree.fit(X_train,y_train)
y_pred = dtree.predict(X_test)
print("訓練資料準確率:",accuracy_score(y_true = y_train, y_pred = dtree.predict(X_train)))
print("測試資料準確率:",accuracy_score(y_true = y_test, y_pred = y_pred))
執行示例 »
基礎分類器在資料集上的表現相當不錯,在測試資料集上以當前引數(如果未設定 random_state 引數,可能會出現不同的結果)實現了 82% 的準確率。
現在我們有了測試資料集的基準準確率,我們可以看看 Bagging 分類器如何超越單個決策樹分類器。
廣告
建立 Bagging 分類器
對於 Bagging,我們需要設定引數 n_estimators,這是我們的模型將聚合的基礎分類器數量。
對於這個樣本資料集,估計器數量相對較低,通常會探索更大的範圍。超引數調整通常透過網格搜尋完成,但現在我們將使用一組選定的估計器數量值。
我們首先匯入必要的模型。
來自 sklearn.ensemble 匯入 BaggingClassifier
現在讓我們建立一系列值來表示我們希望在每個整合中使用的估計器數量。
estimator_range = [2,4,6,8,10,12,14,16]
為了瞭解 Bagging 分類器在不同 n_estimators 值下的表現,我們需要一種方法來迭代這些值範圍並存儲每個整合的結果。為此,我們將建立一個 for 迴圈,將模型和分數儲存在單獨的列表中,以便後續視覺化。
注意:BaggingClassifier 中基礎分類器的預設引數是 DicisionTreeClassifier,因此在例項化 bagging 模型時無需設定它。
models = []
scores = []
for n_estimators in estimator_range
# 建立 bagging 分類器
clf = BaggingClassifier(n_estimators = n_estimators, random_state = 22)
# 擬合模型
clf.fit(X_train, y_train)
# 將模型和分數追加到各自的列表
models.append(clf)
scores.append(accuracy_score(y_true = y_test, y_pred = clf.predict(X_test)))
儲存了模型和分數後,我們現在可以視覺化模型效能的改進。
import matplotlib.pyplot as plt
# 生成分數與估計器數量的圖表
plt.figure(figsize=(9,6))
plt.plot(estimator_range, scores)
# 調整標籤和字型(使其可見)
plt.xlabel("n_estimators", fontsize = 18)
plt.ylabel("score", fontsize = 18)
plt.tick_params(labelsize = 16)
# 視覺化圖表
plt.show()
示例
匯入必要資料並評估 BaggingClassifier 效能。
import matplotlib.pyplot as plt
來自 sklearn 匯入資料集
來自 sklearn.model_selection 匯入 train_test_split
來自 sklearn.metrics 匯入 accuracy_score
來自 sklearn.ensemble 匯入 BaggingClassifier
data = datasets.load_wine(as_frame = True)
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 22)
estimator_range = [2,4,6,8,10,12,14,16]
models = []
scores = []
for n_estimators in estimator_range
# 建立 bagging 分類器
clf = BaggingClassifier(n_estimators = n_estimators, random_state = 22)
# 擬合模型
clf.fit(X_train, y_train)
# 將模型和分數追加到各自的列表
models.append(clf)
scores.append(accuracy_score(y_true = y_test, y_pred = clf.predict(X_test)))
# 生成分數與估計器數量的圖表
plt.figure(figsize=(9,6))
plt.plot(estimator_range, scores)
# 調整標籤和字型(使其可見)
plt.xlabel("n_estimators", fontsize = 18)
plt.ylabel("score", fontsize = 18)
plt.tick_params(labelsize = 16)
# 視覺化圖表
plt.show()
結果
結果解釋
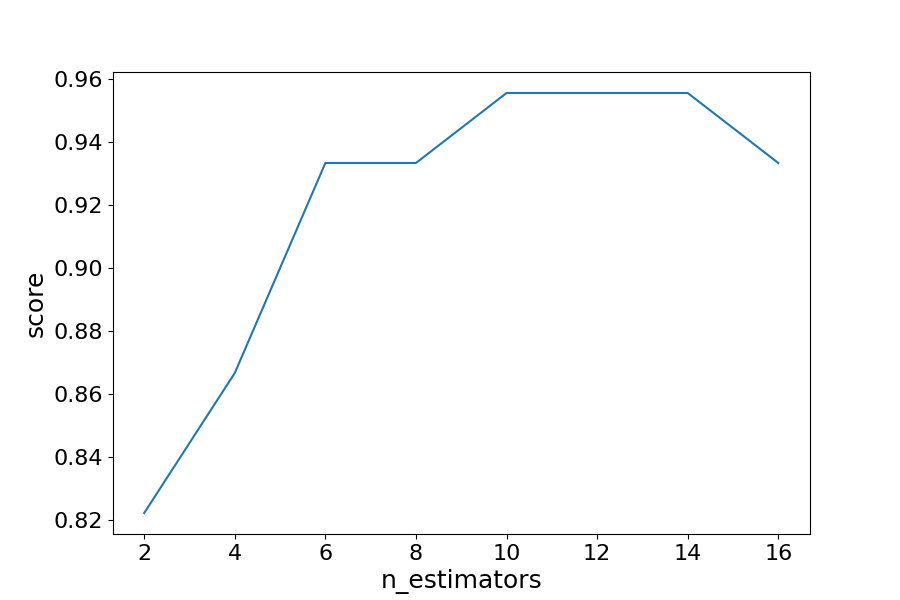
透過迭代不同數量的估計器,我們可以看到模型效能從 82.2% 提高到 95.5%。在 14 個估計器之後,準確率開始下降,同樣,如果您設定不同的 random_state,您看到的值將有所不同。這就是為什麼最好使用交叉驗證來確保結果穩定。
在這種情況下,在識別葡萄酒型別時,準確率提高了 13.3%。
另一種評估形式
由於自舉選擇隨機觀測子集來建立分類器,因此在選擇過程中會遺漏一些觀測。這些“袋外”觀測值可以用於評估模型,類似於測試集。請記住,袋外估計可能會高估二分類問題中的誤差,並且應僅作為其他指標的補充。
在上次練習中,我們看到 12 個估計器產生了最高的準確率,所以我們將用它來建立我們的模型。這次將引數 oob_score 設定為 true,以使用袋外分數評估模型。
示例
使用袋外指標建立模型。
來自 sklearn 匯入資料集
來自 sklearn.model_selection 匯入 train_test_split
來自 sklearn.ensemble 匯入 BaggingClassifier
data = datasets.load_wine(as_frame = True)
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 22)
oob_model = BaggingClassifier(n_estimators = 12, oob_score = True,random_state = 22)
oob_model.fit(X_train, y_train)
print(oob_model.oob_score_)
執行示例 »
由於 OOB 中使用的樣本和測試集不同,並且資料集相對較小,因此準確率存在差異。它們完全相同的情況很少見,OOB 應該作為估計誤差的快速方法,但不是唯一的評估指標。
從 Bagging 分類器生成決策樹
正如在決策樹課程中看到的那樣,可以繪製模型建立的決策樹。還可以檢視組成聚合分類器的各個決策樹。這有助於我們更直觀地理解 Bagging 模型如何得出預測。
注意:這僅適用於較小的資料集,其中樹相對較淺且較窄,易於視覺化。
我們需要從 sklearn.tree 匯入 plot_tree 函式。可以透過更改您希望視覺化的估計器來繪製不同的樹。
示例
從 Bagging 分類器生成決策樹
來自 sklearn 匯入資料集
來自 sklearn.model_selection 匯入 train_test_split
來自 sklearn.ensemble 匯入 BaggingClassifier
來自 sklearn.tree 匯入 plot_tree
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 22)
clf = BaggingClassifier(n_estimators = 12, oob_score = True,random_state = 22)
clf.fit(X_train, y_train)
plt.figure(figsize=(30, 20))
plot_tree(clf.estimators_[0], feature_names = X.columns)
結果
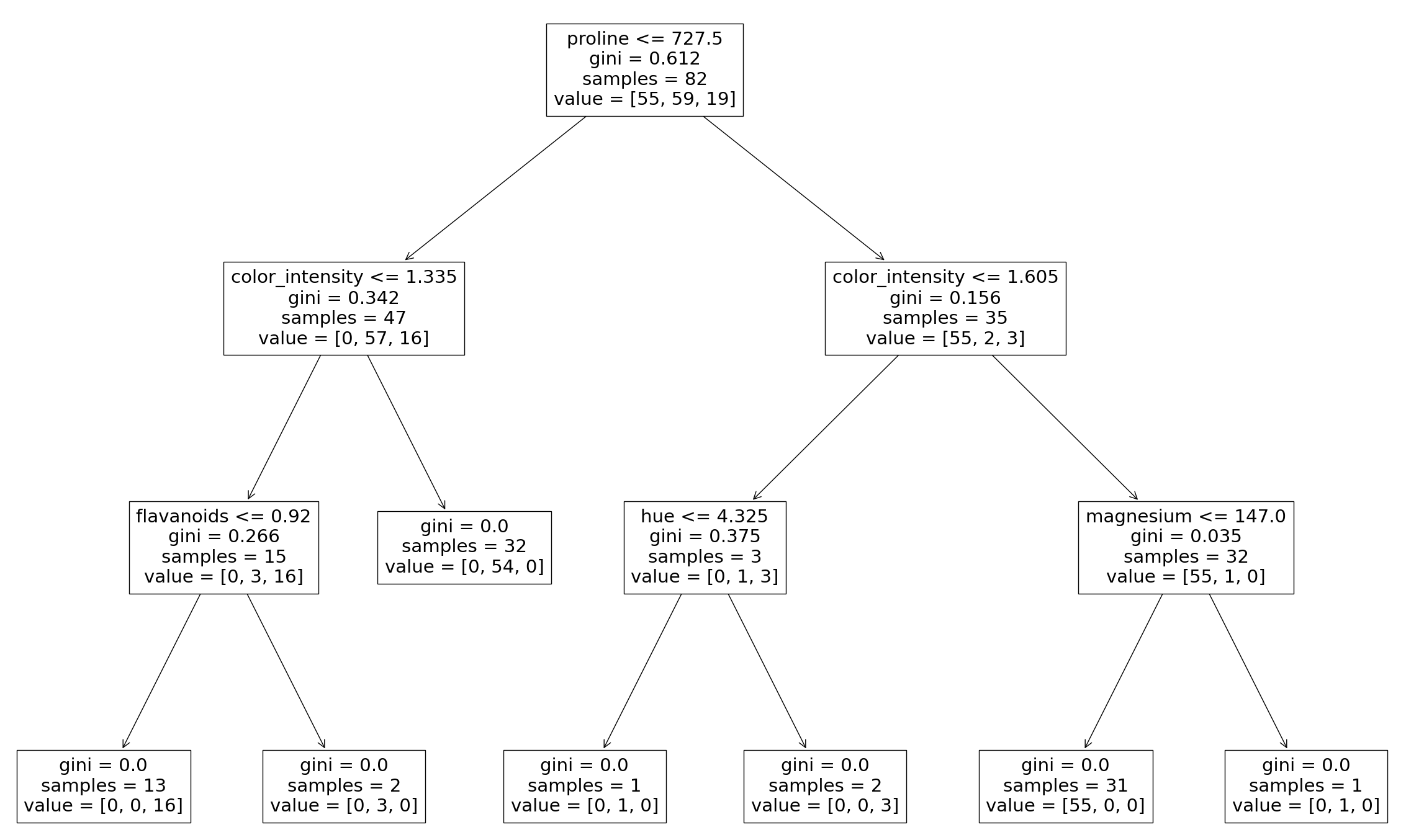
這裡我們只看到第一個決策樹,它用於對最終預測進行投票。同樣,透過更改分類器的索引,您可以檢視已聚合的每個樹。

