機器學習 - 層次聚類
在此頁面上,W3schools.com 與 紐約資料科學學院 合作,為我們的學生提供數字培訓內容。
層次聚類
層次聚類是一種無監督學習方法,用於對資料點進行聚類。該演算法透過測量資料點之間的不相似性來構建簇。無監督學習意味著模型無需訓練,我們也不需要“目標”變數。這種方法可用於任何資料,以視覺化和解釋單個數據點之間的關係。
在這裡,我們將使用層次聚類對資料點進行分組,並透過樹狀圖和散點圖來視覺化這些簇。
它是如何工作的?
我們將使用凝聚聚類,這是一種層次聚類方法,遵循自下而上的方法。我們從將每個資料點視為一個單獨的簇開始。然後,我們將距離最短的簇連線起來,形成更大的簇。重複此步驟,直到形成一個包含所有資料點的大簇。
層次聚類要求我們同時確定距離和連線方法。我們將使用歐幾里得距離和 Ward 連線方法,該方法試圖最小化簇之間的方差。
示例
首先,視覺化一些資料點
import numpy as np
import matplotlib.pyplot as plt
x = [4, 5, 10, 4, 3, 11, 14 , 6, 10, 12]
y = [21, 19, 24, 17, 16, 25, 24, 22, 21, 21]
plt.scatter(x, y)
plt.show()
結果
廣告
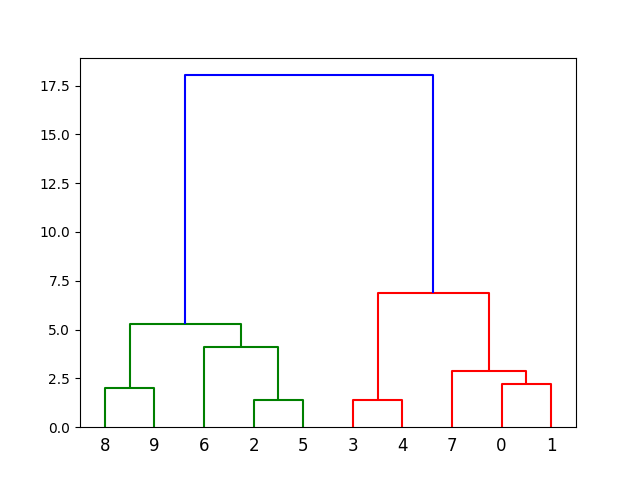
現在,我們使用歐幾里得距離計算 Ward 連線,並使用樹狀圖進行視覺化。
示例
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
x = [4, 5, 10, 4, 3, 11, 14 , 6, 10, 12]
y = [21, 19, 24, 17, 16, 25, 24, 22, 21, 21]
data = list(zip(x, y))
linkage_data = linkage(data, method='ward', metric='euclidean')
dendrogram(linkage_data)
plt.show()
結果
示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import AgglomerativeClustering
x = [4, 5, 10, 4, 3, 11, 14 , 6, 10, 12]
y = [21, 19, 24, 17, 16, 25, 24, 22, 21, 21]
data = list(zip(x, y))
hierarchical_cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
labels = hierarchical_cluster.fit_predict(data)
plt.scatter(x, y, c=labels)
plt.show()
結果
示例解釋
匯入所需的模組。
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.cluster import AgglomerativeClustering
你可以在我們的 “Matplotlib 教程”中瞭解 Matplotlib 模組。
您可以在我們的 SciPy 教程 中瞭解 SciPy 模組。
NumPy 是一個用於在 Python 中處理陣列和矩陣的庫,您可以在我們的 NumPy 教程 中瞭解 NumPy 模組。
scikit-learn 是一個流行的機器學習庫。
建立類似於資料集中兩個變數的陣列。請注意,雖然這裡我們只使用了兩個變數,但此方法適用於任何數量的變數。
x = [4, 5, 10, 4, 3, 11, 14 , 6, 10, 12]
y = [21, 19, 24, 17, 16, 25, 24, 22, 21, 21]
將資料轉換為一組點。
data = list(zip(x, y))
print(data)
結果
[(4, 21), (5, 19), (10, 24), (4, 17), (3, 16), (11, 25), (14, 24), (6, 22), (10, 21), (12, 21)]
計算所有不同點之間的連線。這裡我們使用簡單的歐幾里得距離度量和 Ward 連線,它試圖最小化簇之間的方差。
linkage_data = linkage(data, method='ward', metric='euclidean')
最後,在樹狀圖中繪製結果。此圖將向我們展示從底部(單個點)到頂部(包含所有資料點的一個簇)的簇的層次結構。
plt.show() 允許我們視覺化樹狀圖,而不僅僅是原始的連線資料。
dendrogram(linkage_data)
plt.show()
結果
scikit-learn 庫允許我們以不同的方式使用層次聚類。首先,我們使用相同的歐幾里得距離和 Ward 連線初始化 AgglomerativeClustering 類,並指定 2 個簇。
hierarchical_cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
可以對我們的資料呼叫 .fit_predict 方法,以使用針對我們選擇的簇數量定義的引數來計算簇。
labels = hierarchical_cluster.fit_predict(data) print(labels)
結果
[0 0 1 0 0 1 1 0 1 1]
最後,如果我們繪製相同的資料並使用層次聚類方法為每個索引分配的標籤來著色點,我們可以看到每個點所屬的簇。
plt.scatter(x, y, c=labels)
plt.show()
結果

