資料科學 - 資料準備
在分析資料之前,資料科學家必須提取資料,並使其乾淨且有價值。
使用 Pandas 提取和讀取資料
在分析資料之前,必須先匯入/提取資料。
在下面的示例中,我們將展示如何使用 Python 中的 Pandas 匯入資料。
我們使用 read_csv() 函式匯入帶有健康資料的 CSV 檔案
示例
import pandas as pd
health_data = pd.read_csv("data.csv", header=0, sep=",")
print(health_data)
自己動手試一試 »
示例解釋
- 匯入 Pandas 庫
- 將資料框命名為
health_data。 header=0表示變數名的標題在第一行(請注意,在 Python 中 0 表示第一行)sep=","表示 "," 用作值之間的分隔符。這是因為我們使用的是 .csv 檔案型別(逗號分隔值)
提示: 如果您的 CSV 檔案很大,可以使用 head() 函式僅顯示前 5 行
示例
import pandas as pd
health_data = pd.read_csv("data.csv", header=0, sep=",")
print(health_data.head())
自己動手試一試 »
資料清理
檢視匯入的資料。如您所見,資料是“髒”的,包含錯誤或未註冊的值
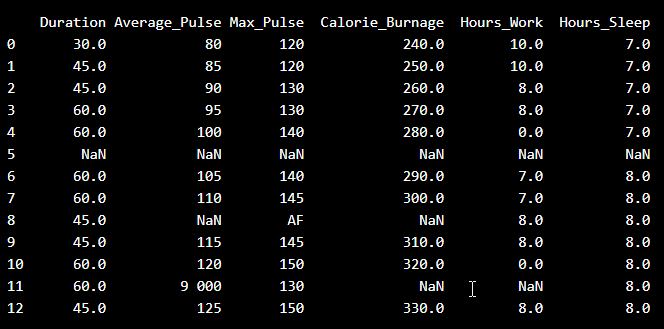
- 有些欄位是空白的
- 平均脈搏 9000 是不可能的
- 由於空格分隔符,9000 將被視為非數字
- 最大脈搏的一個觀測值被標記為“AF”,這沒有意義
因此,我們必須清理資料才能進行分析。
刪除空白行
我們看到非數字值(9000 和 AF)與缺失值在同一行。
解決方案:我們可以刪除包含缺失觀測值的行來解決這個問題。
當我們使用 Pandas 載入資料集時,所有空白單元格都會自動轉換為“NaN”值。
因此,刪除 NaN 單元格可以得到一個可以分析的乾淨資料集。
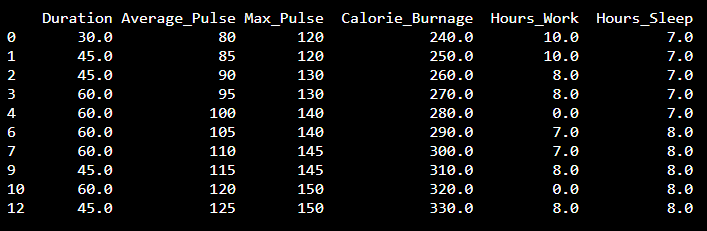
我們可以使用 dropna() 函式刪除 NaN。axis=0 表示我們要刪除所有包含 NaN 值的行
結果是沒有 NaN 行的資料集
資料類別
為了分析資料,我們還需要了解我們正在處理的資料型別。
資料可以分為兩類
- 定量資料 - 可以表示為數字或可以量化。可分為兩類
- 離散資料:數字被計為“整數”,例如班級人數,足球比賽進球數
- 連續資料:數字可以是無限精度的。例如,一個人的體重,鞋碼,溫度
- 定性資料 - 不能表示為數字,也不能量化。可分為兩類
- 標稱資料:例如:性別、髮色、種族
- 有序資料:例如:學校成績(A、B、C),經濟狀況(低、中、高)
通過了解資料型別,您將能夠知道分析資料時應使用哪種技術。
資料型別
我們可以使用 info() 函式列出我們資料中的資料型別:
結果
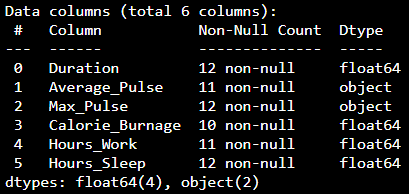
我們看到這個資料集有兩種不同的資料型別
- Float64
- 物件
在這裡,我們不能使用物件來進行計算和分析。我們必須將物件型別轉換為 float64(在 Python 中,float64 是帶小數的數字)。
我們可以使用 astype() 函式將資料轉換為 float64。
以下示例將“Average_Pulse”和“Max_Pulse”轉換為 float64 資料型別(其他變數已經是 float64 資料型別)
示例
health_data["Average_Pulse"] = health_data['Average_Pulse'].astype(float)
health_data["Max_Pulse"] = health_data["Max_Pulse"].astype(float)
print (health_data.info())
自己動手試一試 »
結果
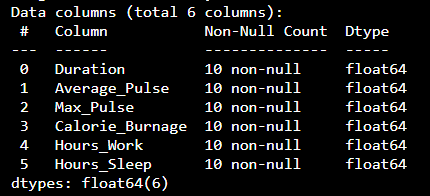
現在,資料集只有 float64 資料型別。
分析資料
清理完資料集後,我們就可以開始分析資料了。
我們可以在 Python 中使用 describe() 函式來總結資料
結果
| 持續時間 | Average_Pulse | Max_Pulse | Calorie_Burnage | Hours_Work | Hours_Sleep | |
|---|---|---|---|---|---|---|
| Count | 10.0 | 10.0 | 10.0 | 10.0 | 10.0 | 10.0 |
| 均值 | 51.0 | 102.5 | 137.0 | 285.0 | 6.6 | 7.5 |
| Std | 10.49 | 15.4 | 11.35 | 30.28 | 3.63 | 0.53 |
| Min | 30.0 | 80.0 | 120.0 | 240.0 | 0.0 | 7.0 |
| 25% | 45.0 | 91.25 | 130.0 | 262.5 | 7.0 | 7.0 |
| 50% | 52.5 | 102.5 | 140.0 | 285.0 | 8.0 | 7.5 |
| 75% | 60.0 | 113.75 | 145.0 | 307.5 | 8.0 | 8.0 |
| Max | 60.0 | 125.0 | 150.0 | 330.0 | 10.0 | 8.0 |
- Count - 計算觀測值的數量
- 均值 - 平均值
- Std - 標準差(在統計學章節中解釋)
- Min - 最小值
- 25%, 50% 和 75% 是百分位數(在統計學章節中解釋)
- Max - 最大值

